Python装饰器&流处理技术
Python装饰器
解释概念
Python中的装饰器是一种用于修改或扩展函数或类的行为的语法结构。装饰器通常是一个函数或类,它接受一个函数或类作为参数,并返回一个新的函数或类。
装饰器可以用于许多不同的目的,例如:
- 添加日志记录或调试信息,以便跟踪函数的执行过程和结果。
- 对函数或类的参数进行验证或修改,以确保它们符合特定的规则或格式。
- 对函数或类进行缓存或记忆化,以避免重复计算或提高性能。
- 添加身份验证或授权逻辑,以确保只有授权用户才能调用函数或类。
- 实现面向切面编程(AOP),以分离横切关注点(如日志记录、性能统计等)和业务逻辑。
Python中的装饰器使用@语法来应用,例如:
这将把@decorator def my_function(): # do somethingmy_function函数传递给decorator装饰器函数,并将其替换为新的函数,该函数包装了原始函数并修改了其行为。
关于装饰器全局变量的使用(接口)
装饰器本质上是一个函数,因此它可以访问任何全局变量。
当在装饰器中使用全局变量时,需要注意以下几点:
- 在装饰器中声明全局变量需要使用
global关键字。 - 在装饰器中使用全局变量,需要确保该变量已经被定义和初始化,否则会引发
NameError异常。 - 全局变量可能会被多个线程或进程访问,因此需要考虑并发安全问题。
- 在装饰器中使用全局变量可能会导致代码的可读性和可维护性降低,因此应尽可能避免使用全局变量。
以下是一个简单的例子,演示如何在装饰器中使用全局变量:
在上面的例子中,我们定义了一个全局变量count = 0 def counter(func): def wrapper(*args, **kwargs): global count count += 1 print(f"Function {func.__name__} was called {count} times.") return func(*args, **kwargs) return wrapper @counter def foo(): print("Hello, world!") foo() # Function foo was called 1 times. foo() # Function foo was called 2 times.count,并在装饰器counter中使用了它。
装饰器counter用于统计函数被调用的次数,每次调用时count加1,并输出调用次数。
函数foo被装饰后,每次调用都会输出调用次数。
除了在装饰器函数内部使用 global 关键字,还可以在装饰器函数外部使用 global 关键字来声明全局变量,并在装饰器内部访问和修改该变量的值:
count = 0
def count_calls(func):
def wrapper(*args, **kwargs):
global count
count += 1
print(f"Function {func.__name__} has been called {count} times")
return func(*args, **kwargs)
return wrapper
@count_calls
def my_function():
global count
if count % 2 == 0:
print("Hello World!")
else:
print("Hi there!")
my_function()
my_function()
my_function()
在这个例子中,我们声明了全局变量 count,并在装饰器内部和外部使用了 global 关键字。
在 my_function 函数内部,我们检查 count 的值是否为偶数,并打印不同的消息。
由于装饰器在每次调用 my_function 函数时都会增加 count 的值,因此 my_function 函数每次都会打印不同的消息。
需要注意的是,在使用全局变量时要小心,因为全局变量可能会在代码中的任何地方进行修改,这可能会导致出现意外的行为。
因此,最好将全局变量用于只读目的,或者在使用时采用适当的同步机制来避免竞争条件。
当然,除了 global 关键字之外,还可以使用其他的方式来在装饰器中引用外部变量。以下是一些常用的方法:
- 使用闭包:在装饰器函数内部定义一个内部函数,并在内部函数中引用外部变量
(由于内部函数可以访问外部函数的变量) - 使用类:将装饰器实现为一个类,并在类中引用外部变量
(由于类实例可以存储变量状态)
无论是使用 global 关键字、闭包还是类,都可以在装饰器中引用外部变量。
除了上面所提到的方法,还可以将变量作为参数传递给装饰器。
这种方式通常适用于装饰器函数需要访问某些变量,但不希望将这些变量声明为全局变量的情况。
通过将变量作为参数传递给装饰器,我们可以更灵活地控制装饰器的行为,但同时也会增加代码的复杂度。因此,在选择使用这种方式时,需要权衡利弊,并根据具体的情况选择最适合的实现方式。
除了在装饰器中使用 global 关键字、闭包、类或参数等方式引用外部变量之外,还可以使用 functools 模块中的 wraps 装饰器来保留被装饰函数的元信息。
具体来说,wraps 装饰器可以用来保留被装饰函数的名称、文档字符串、参数签名等元信息,从而使得被装饰函数更加易于调试和理解。
流处理技术
概念解析
流处理技术是一种处理数据的方式,它是指持续接收和处理流式数据的方式。
与批处理不同,流处理将数据视为连续的数据流,而不是离散的数据集合。
应用领域
流处理技术的主要用途是实时分析和处理数据。
通过流处理技术,可以快速处理大量的实时数据,并从中提取有价值的信息。
流处理技术通常使用流处理引擎来实现,流处理引擎通常提供一系列的API和工具。
用于处理数据流、实时处理和聚合数据、分析数据和发送数据到其他系统。
流处理引擎还可以与其他系统和工具集成,例如数据库、数据仓库、消息队列等。
使用方法
在使用流处理技术时,需要考虑以下几个方面:
(1)数据来源和输入方式:从不同的数据源中读取实时数据流。
(2)流处理引擎的选择:根据具体的业务需求和系统架构选择适合的流处理引擎。
(Apache Flink、Apache Kafka Streams、Apache Spark Streaming等)
(3)数据处理逻辑:定义数据处理逻辑。
(4)数据输出方式:传输和存储处理后的数据。
简单的示例
下面是个使用Flask和cv2框架编写的一个用于播放视频的Python流处理脚本
from flask import Flask, Response
import cv2
app = Flask(__name__)
camera = cv2.VideoCapture("1.mp4")
def generate_frames():
while True:
success, frame = camera.read()
if success:
ret, buffer = cv2.imencode('.jpg', frame)
frame = buffer.tobytes()
yield (b'--frame\r\nContent-Type: image/jpeg\r\n\r\n' + buffer.tobytes() + b'\r\n')
else:
break
@app.route('/')
def video_feed():
return Response(generate_frames(),mimetype='multipart/x-mixed-replace;boundary=frame')
if __name__ == '__main__':
app.run()
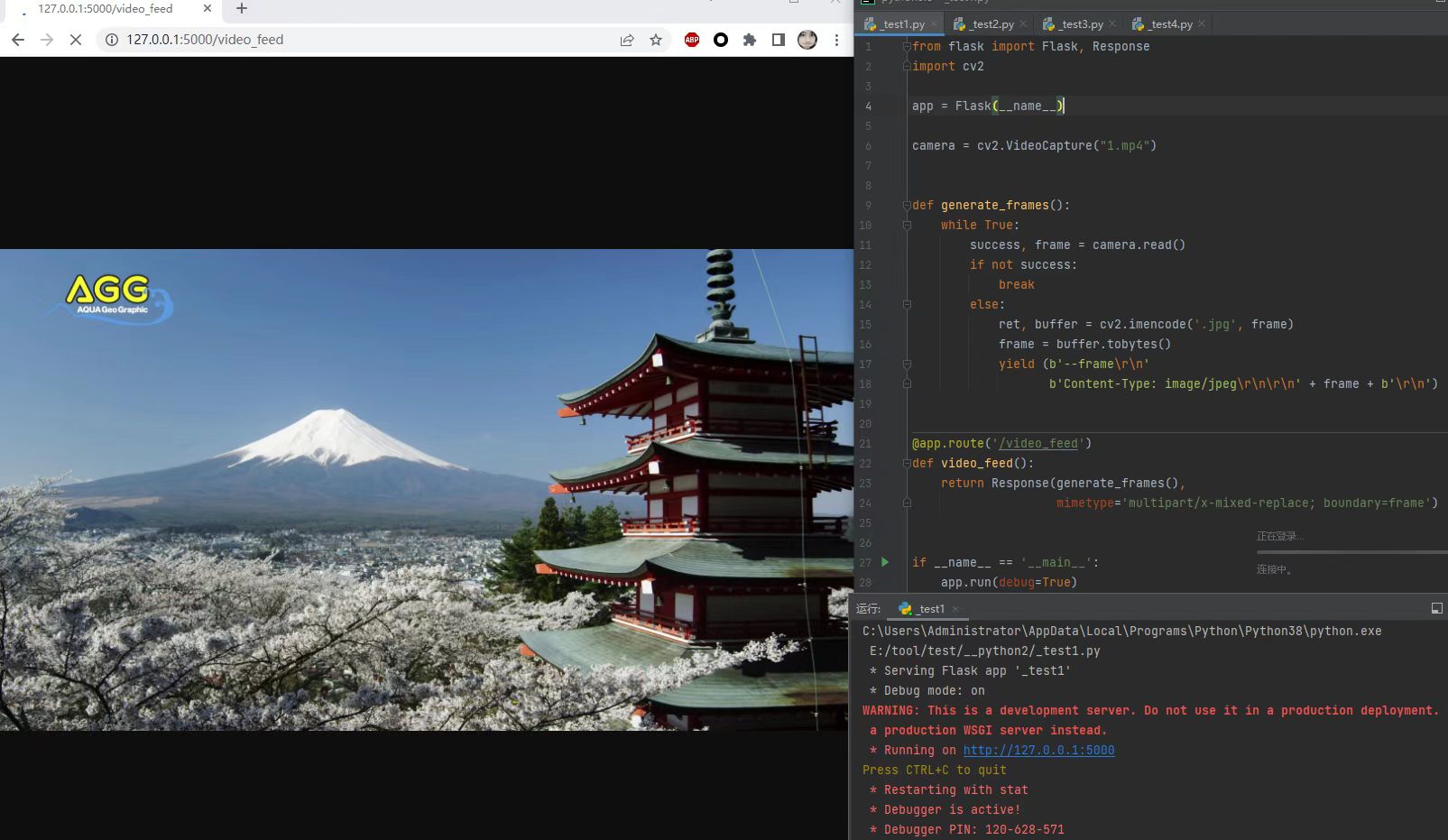
但是这样子做出来的很大缺陷:
1.没办法调倍速
2.没声音
3.不能循环播放之类的
但是,要想解决上面这些问题只需要再添加两行代码!!!
一行代码启动docker版nginx-rtmp服务
另一行代码使用FFmpeg推流,指定服务器地址
(我没试过,出问题别找我)